

Audio Transcription Application - Powered by Faster Whisper
A comprehensive audio transcription desktop application that simplifies the process of converting speech to text. Built with PyQt5 for the graphical interface and powered by Faster Whisper, this application offers robust features including multi-language transcription with automatic language detection, flexible model selection for accuracy/speed balance, hardware acceleration (CPU/GPU with CUDA support), result persistence, and real-time progress monitoring. The application provides an intuitive and user-friendly interface suitable for both beginners and advanced users.
Problem Statement
Transcribing audio files manually is time-consuming and error-prone. Existing solutions often lack user-friendly interfaces, require extensive technical expertise to set up, or impose restrictive hardware limitations. Users need an accessible, efficient solution for converting speech to text across multiple languages.
My Approach
Created a desktop application using PyQt5 that wraps the Faster Whisper transcription model in an intuitive, accessible GUI. Implemented support for multiple audio formats (mp3, wav, m4a, flac), various model sizes (tiny to large-v3) for accuracy/speed trade-offs, and GPU acceleration with CUDA 9.0 and cuDNN 11.8 for significantly faster processing. Added features including automatic language detection, result persistence to text files, real-time progress monitoring, and flexible hardware configuration (CPU/GPU selection). The application is optimized for Anaconda environments with comprehensive setup automation.
Key Outcomes
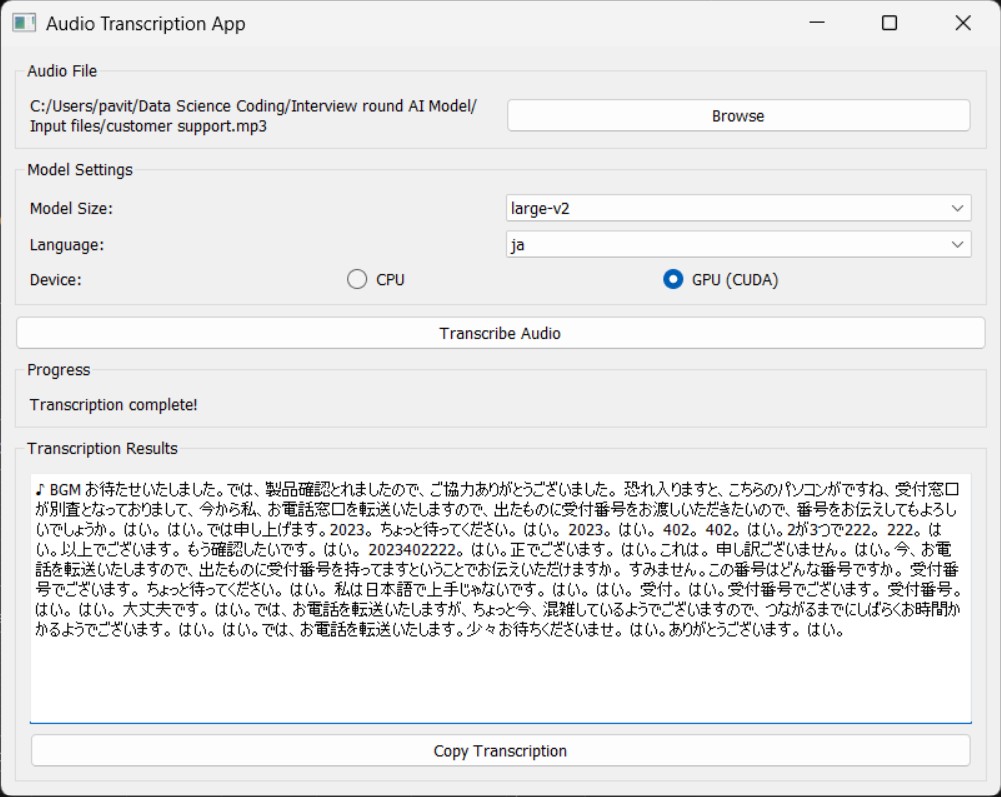
- Intuitive GUI enabling non-technical users to transcribe audio without command-line expertise
- Support for 7 model sizes (tiny, base, small, medium, large-v2, large-v3) with configurable accuracy/speed balance
- Multi-language transcription supporting 50+ languages including English, Japanese, Chinese, German, Spanish, Russian, Korean, French, and more
- GPU acceleration reducing transcription time from minutes to seconds for 5-minute audio files
- Real-time progress monitoring with live updates and confidence level display
- Automatic language detection with displayed confidence metrics
- Result persistence with easy-to-access text file exports
- Support for multiple audio formats (mp3, wav, m4a, flac)
- Detected language and confidence level display during transcription
Screenshots
Tech Stack
Tags
Project Info
- Status
- Completed
- Category
- Personal
- Created
- 1 year ago
- Ended
- Feb 2025